 Выход
ВыходВопрос 2. Модели представления данных. Постреляционная, многомерная, объектно-ориентированная модели данных. Привести примеры.
| Добавил: | DMT | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Дата создания: | 30 декабря 2007, 16:23 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Дата обновления: | 30 декабря 2007, 19:59 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Просмотров: | 44122 последний сегодня, 7:48 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Комментариев: | 0 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Постреляционная модель Классическая реляционная модель предполагает неделимость данных, хранящихся в полях записей таблиц. Постреляционная модель представляет собой расширенную реляционную модель, снимающую ограничение неделимости данных. Модель допускает многозначные поля – поля, значения которых состоят из подзначений . Набор значений многозначных полей считается самостоятельной таблицей, встроенной в основную таблицу. На рис. 2.6 на примере информации о накладных и товарах для сравнения приведено представление одних и тех же данных с помощью реляционной (а) и постреляционной (б) моделей. Из рисунка видно, что по сравнению с реляционной моделью в постреляционной модели данные хранятся более эффективно, а при обработке не потребуется выполнять операцию соединения данных из двух таблиц. а) Накладные Накладные-товары
б) Накладные
Рис. 2.6. Структуры данных реляционной и постреляционной моделей Поскольку постреляционная модель допускает хранение в таблицах ненормализованных данных, возникает проблема обеспечения целостности и непротиворечивости данных. Эта проблема решается включением в СУБД соответствующих механизмов. Достоинством постреляционной модели является возможность представления совокупности связанных реляционных таблиц одной постреляционной таблицей. Это обеспечивает высокую наглядность представления информации и повышение эффективности ее обработки. Недостатком постреляционной модели является сложность решения проблемы обеспечения целостности и непротиворечивости хранимых данных. Рассмотренная постреляционная модель данных поддерживается СУБД uniVers . К числу других СУБД, основанных на постреляционной модели данных, относятся также системы Bubba и Dasdb .
Многомерная модель Многомерный подход к представлению данных появился практически одновременно с реляционным , но интерес к многомерным СУБД стал приобретать массовый характер с середины 90-х годов. Толчком послужила в 1993 году статья Э. Кодда. В ней были сформулированы 12 основных требований к системам класса OLAP ( OnLine Analytical Processing – оперативная аналитическая обработка), важнейшие из которых связаны с возможностями концептуального представления и обработки многомерных данных. В развитии концепций информационных систем можно выделить следующие два направления: • системы оперативной (транзакционной) обработки; • системы аналитической обработки (системы поддержки принятия решений). Реляционные СУБД предназначались для информационных систем оперативной обработки информации и в этой области весьма эффективны. В системах аналитической обработки они показали себя несколько неповоротливыми и недостаточно гибкими. Более эффективными здесь оказываются многомерные СУБД. Многомерные СУБД являются узкоспециализированными СУБД, предназначенными для интерактивной аналитической обработки информации. Основные понятия, используемые в этих СУБД: агрегируемость , историчность и прогнозируемость. Агрегируемость данных означает рассмотрение информации на различных уровнях ее обобщения. В информационных системах степень детальности представления информации для пользователя зависит от его уровня: аналитик, пользователь, управляющий, руководитель. Историчность данных предполагает обеспечение высокого уровня статичности собственно данных и их взаимосвязей, а также обязательность привязки данных ко времени. Прогнозируемость данных подразумевает задание функций прогнозирования и применение их к различным временным интервалам . Многомерность модели данных означает не многомерность визуализации цифровых данных, а многомерное логическое представление структуры информации при описании и в операциях манипулирования данными. По сравнению с реляционной моделью многомерная организация данных обладает более высокой наглядностью и информативностью. Для иллюстрации на рис. 2.7 приведены реляционное (а) и многомерное (б) представления одних и тех же данных об объемах продаж автомобилей. Основные понятия многомерных моделей данных: измерение и ячейка. Измерение – это множество однотипных данных, образующих одну из граней гиперкуба. В многомерной модели измерения играют роль индексов, служащих для идентификации конкретных значений в ячейках гиперкуба. Ячейка – это поле, значение которого однозначно определяется фиксированным набором измерений. Тип поля чаще всего определен как цифровой. В зависимости от того, как формируются значения некоторой ячейки, она может быть переменной (значения изменяются и могут быть загружены из внешнего источника данных или сформированы программно) либо формулой (значения, подобно формульным ячейкам электронных таблиц, вычисляются по заранее заданным формулам). а) б)
Рис. 2.7. Реляционное и многомерное представление данных В примере на рис. 2.7 б каждое значение ячейки Объем продаж однозначно определяется комбинацией временного измерения Месяц продаж и модели автомобиля. На практике зачастую требуется большее количество измерений. Пример трехмерной модели данных приведен на рис. 2.8.
Рис. 2.8. Пример трехмерной модели В существующих многомерных СУБД используются две основных схемы организации данных: гиперкубическая и поликубическая . В поликубической схеме предполагается, что в БД может быть определено несколько гиперкубов с различной размерностью и с различными измерениями в качестве граней. Примером системы, поддерживающей поликубический вариант БД, является сервер Oracle Express Server . В случае гиперкубической схемы предполагается, что все ячейки определяются одним и тем же набором измерений. Это означает, что при наличии нескольких гиперкубов в БД, все они имеют одинаковую размерность и совпадающие измерения. Основным достоинством многомерной модели данных является удобство и эффективность аналитической обработки больших объемов данных, связанных со временем. Недостатком многомерной модели данных является ее громоздкость для простейших задач обычной оперативной обработки информации. Примерами систем, поддерживающими многомерные модели данных, является Essbase , Media Multi - matrix , Oracle Express Server , Cache . Существуют программные продукты, например Media / MR , позволяющие одновременно работать с многомерными и с реляционными БД.
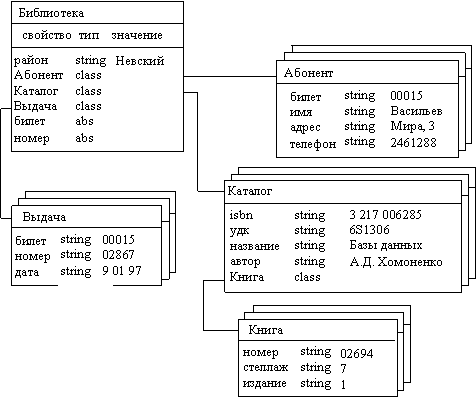
Объектно-ориентированная модель В объектно-ориентированной модели при представлении данных имеется возможность идентифицировать отдельные записи базы данных. Между записями и функциями их обработки устанавливаются взаимосвязи с помощью механизмов, подобных соответствующим средствам в объектно-ориентированных языках программирования. Стандартизированная объектно-ориентированная модель описана в рекомендациях стандарта ODMG -93 ( Object Database Management Group – группа управления объектно-ориентированными базами данных). Рассмотрим упрощенную модель объектно-ориентированной БД. Структура объектно-ориентированной БД графически представима в виде дерева, узлами которого являются объекты. Свойства объектов описываются некоторым стандартным типом или типом, конструируемым пользователем (определяется как class ). Значение свойства типа class есть объект, являющийся экземпляром соответствующего класса. Каждый объект-экземпляр класса считается потомком объекта, в котором он определен как свойство. Объект-экземпляр класса принадлежит своему классу и имеет одного родителя. Родовые отношения в БД образуют связн ую ие рархию объектов. Пример логической структуры объектно-ориентированной БД библиотечного дела приведен на рис. 2.9. Здесь объект типа Библиотека является родительским для объектов-экземпляров классов Абонент , Каталог и Выдача . Различные объекты типа Книг а могут иметь одного или разных родителей. Объекты типа Книга , имеющие одного и того же родителя, должны различаться, по крайней мере, инвентарным номером (уникален для каждого экземпляра книги), но имеют одинаковые значения свойств isb n , удк , названи е и автор . Логическая структура объектно-ориентированной БД внешне похожа на структуру иерархической БД. Основное различие между ними состоит в методах манипулирования данными. Для выполнения действий над данными в рассматриваемой модели БД применяются логические операции, усиленные объектно-ориентированными механизмами инкапсуляции, наследования и полиморфизма. Инкапсуляция ограничивает область видимости имени свойства пределами того объекта, в котором оно определено. Так, если в объект типа Каталог добавить свойство, задающее телефон автора книги и имеющее название телефон , то мы получим одноименные свойства у объектов Абонент и Каталог . Смысл такого свойства будет определяться тем объектом, в который оно инкапсулировано. Наследование , наоборот, распространяет область видимости свойства на всех потомков объекта. Так, всем объектам типа Книга , являющимся потомками объекта типа Каталог , можно приписать свойства объекта-родителя: isbn , удк , название и автор . Если необходимо расширить действие механизма наследования на объекты, не являющиеся непосредственными родственниками (например, между двумя потомками одного родителя), то в их общем предке определяется абстрактное свойство типа abs . Так, определение абстрактных свойств билет и номер в объекте Библиотека приводит к наследованию этих свой ств вс еми дочерними объектами Абонент , Книга и Выдач а. Не случайно, поэтому значения свойства билет классов Абонент и Выдача , показанных на рис. 2.9, являются одинаковыми – 00015. Полиморфизм в объектно-ориентированных языках программирования означает способность одного и того же программного кода работать с разнотипными данными. Другими словами, он означает допустимость в объектах разных типов иметь методы (процедуры или функции) с одинаковыми именами. Во время выполнения объектной программы одни и те же методы оперируют с разными объектами в зависимости от типа аргумента. Применительно к рассматриваемому примеру полиморфизм означает, что объекты класса Книга , имеющие разных родителей из класса Каталог , могут иметь разный набор свойств. Следовательно, программы работы с объектами класса Книга могут содержать полиморфный код. Поиск в объектно-ориентированной БД состоит в выяснении сходства между объектом, задаваемым пользователем, и объектами, хранящимися в БД.
Рис. 2.9. Логическая структура БД библиотечного дела Основным достоинством объектно-ориентированной модели данных в сравнении с реляционной является возможность отображения информации о сложных взаимосвязях объектов. Объектно-ориентированная модель данных позволяет идентифицировать отдельную запись базы данных и определять функции их обработки. Недостатками объектно-ориентированной модели являются высокая понятийная сложность, неудобство обработки данных и низкая скорость выполнения запросов. К объектно-ориентированным СУБД относятся POET , Jasmine , Versant , O 2, ODB - Jupiter , Iris , Orion , Postgres .
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||